Abstract
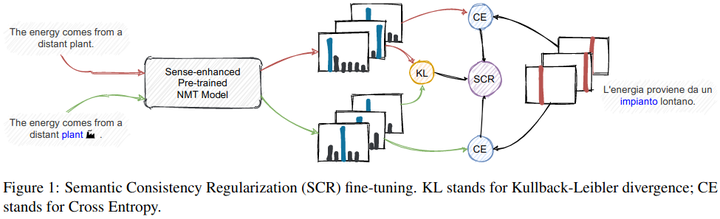
Recent studies have shed some light on a common pitfall of Neural Machine Translation (NMT) models, stemming from their struggle to disambiguate polysemous words without lapsing into their most frequently occurring senses in the training corpus. In this paper, we first provide a novel approach for automatically creating high-precision sense-annotated parallel corpora, and then put forward a specifically tailored fine-tuning strategy for exploiting these sense annotations during training without introducing any additional requirement at inference time. The use of explicit senses proved to be beneficial to reduce the disambiguation bias of a baseline NMT model, while, at the same time, leading our system to attain higher BLEU scores than its vanilla counterpart in 3 language pairs.